|
William Yang I am a 5th-year PhD Computer Science student in the Princeton Visual AI Lab advised by Prof. Olga Russakovsky. Previously, I completed my undergraduate studies at Carnegie Mellon University, where I was advised by Prof. Leila Wehbe and Prof. Robert F. Murphy. My research focuses on understanding and controlling the behavior of multimodal generative models. I am broadly interested in three interconnected questions:
|

|
Selected Publications |
|
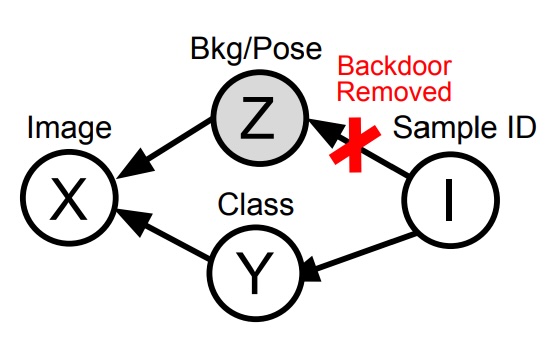
Beyond Objects: Contextual Synthetic Data Generation for Fine-Grained Classification
William Yang, Xindi Wu, Zhiwei Deng, Esin Tureci, Olga Russakovsky CVPR, 2026 arXiv / code In low-data regime, models are especially prone to spurious correlations, and naïvely fine-tuning generative models on a few examples can amplify these biases while reducing diversity. We propose BeyondOBjects (BOB), a method that instead conditions on class-agnostic attributes (like background and pose) to preserve diversity and the model’s prior knowledge, generating synthetic data that improves classification performance. |
|
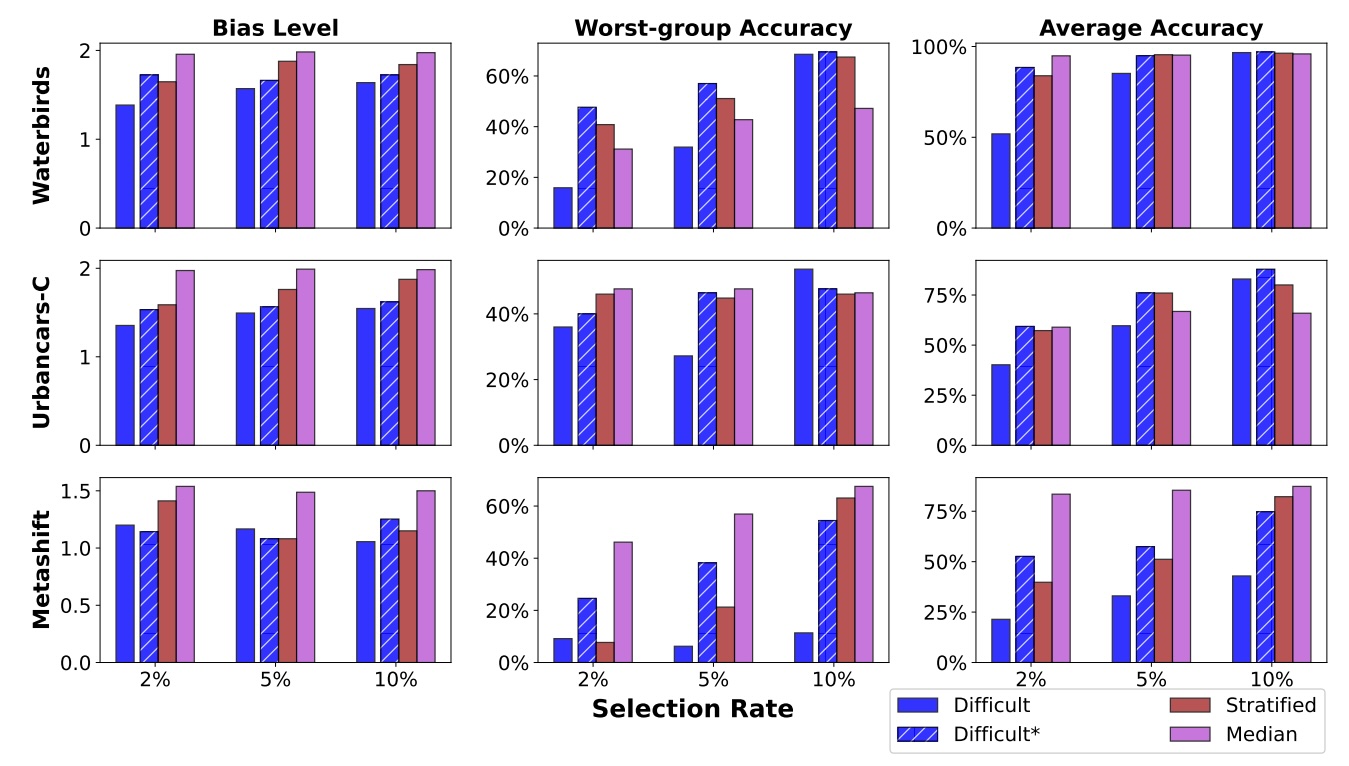
The Impact of Coreset Selection on Spurious Correlations and Group Robustness
Amaya Dharmasiri, William Yang, Polina Kirichenko, Lydia Liu, Olga Russakovsky NeurIPS Datasets and Benchmarks, 2025 arXiv / code In biased datasets, especially under data-efficient regimes, models often rely on spurious correlations, and it is unclear whether coreset selection methods alleviate or exacerbate this issue. This paper provides a comprehensive analysis of how different data selection strategies interact with dataset bias, showing that some methods can unintentionally amplify spurious correlations while others mitigate them to a degree. |

|
What is Dataset Distillation Learning?
William Yang, Ye Zhu, Zhiwei Deng, Olga Russakovsky ICML, 2024 arXiv / code Dataset distillation aims to compress large datasets into a small synthetic set that preserves training performance, but it remains unclear what information these distilled samples actually encode. This paper shows that distilled data is not a general substitute for real data and instead primarily captures information tied to early training dynamics rather than full dataset semantics. Therefore, their usefulness is tightly coupled to the distillation setting and does not generalize broadly outside it. |

|
ImageNet-OOD: Deciphering Modern Out-of-Distribution Detection Algorithms
William Yang*, Byron Zhang*, Olga Russakovsky ICLR, 2024 arXiv / code Out-of-distribution (OOD) detection is complicated by the fact that models can respond similarly to semantically meaningful shifts (new classes) and simpler covariate shifts We shows that many modern OOD methods are more sensitive to covariate shift than to semantic shift, often performing no better than simple baselines. We introduce a cleaner evaluation setting and demonstrates that current gains in OOD detection are much smaller than previously believed for the target problem of semantic shift. |